






什么是网络爬取工具?
AI网页抓取是指使用人工智能从通常无结构的网站中提取数据或信息,并将其转换为可用于各种业务目的和分析的结构化数据的过程。它利用机器学习算法理解和模拟人类的浏览行为,从而高效地收集数据。
好用的前10个AI 网络爬取工具工具有哪些?
|
核心功能
|
如何使用
|
|
|---|---|---|
UseScraper Crawler |
超快速的网页爬取和抓取 |
要使用 UseScraper,只需提供一个网站 URL 并选择所需的输出格式(Markdown 或 JSON)。API 将抓取网站,提取其内容,并按要求提供输出。 |
FetchFox |
人工智能提供支持的网络爬虫 |
要使用FetchFox,您需要从Chrome Web Store安装Chrome扩展。安装完成后,添加您的OpenAI密钥以启用对ChatGPT的访问。然后,创建一个新的爬取作业,并键入您想要提取的数据。访问您想要爬取的页面,并在每个页面上单击一次扩展程序。最后,下载一个包含爬取数据的CSV文件以备将来使用。 |
SingleAPI |
数据抓取 - 使用我们强大的抓取引擎从任何网站提取数据,无需编写任何选择器。 |
在几秒钟内将任何网站转换为API。 |
pegleg.ai |
|
使用Pegleg.ai,只需要提交您怀疑侵犯版权的Patreon或Gumroad链接。平台将自动搜索侵权情况,并代表您发出DMCA版权侵权通知。 |
Webᵀ Crawl by Web Transpose |
|
只需给出一个URL,让网站抓取处理剩下的事情。快速将整个网站和内容(如PDF、FAQ等)转化为微调的提示和矢量数据库的块。 |
PIXMO |
自动化软件,全天候扫描互联网,寻找与您的数字资产匹配的内容 |
1. 将您的图片上传到Pixmo平台。2. Pixmo先进的人工智能技术扫描互联网,寻找与您的数字资产完全匹配的内容。3. 在几秒钟内,Pixmo会显示您的资产被使用的确切URL。4. 提交一个下架申诉给Pixmo团队,并设定一个您想要向侵权者提供的总许可费。5. Pixmo努力为您获取未经授权使用资产的赔偿。 |
WebscrapeAi |
易于使用:只需输入 URL 和要抓取的项目 |
要使用 Webscrape AI,只需输入要抓取的网站的URL,并指定要收集的项目。AI 抓取器将使用先进的算法准确地收集数据。无需编码技能,任何人都可以轻松使用。 |
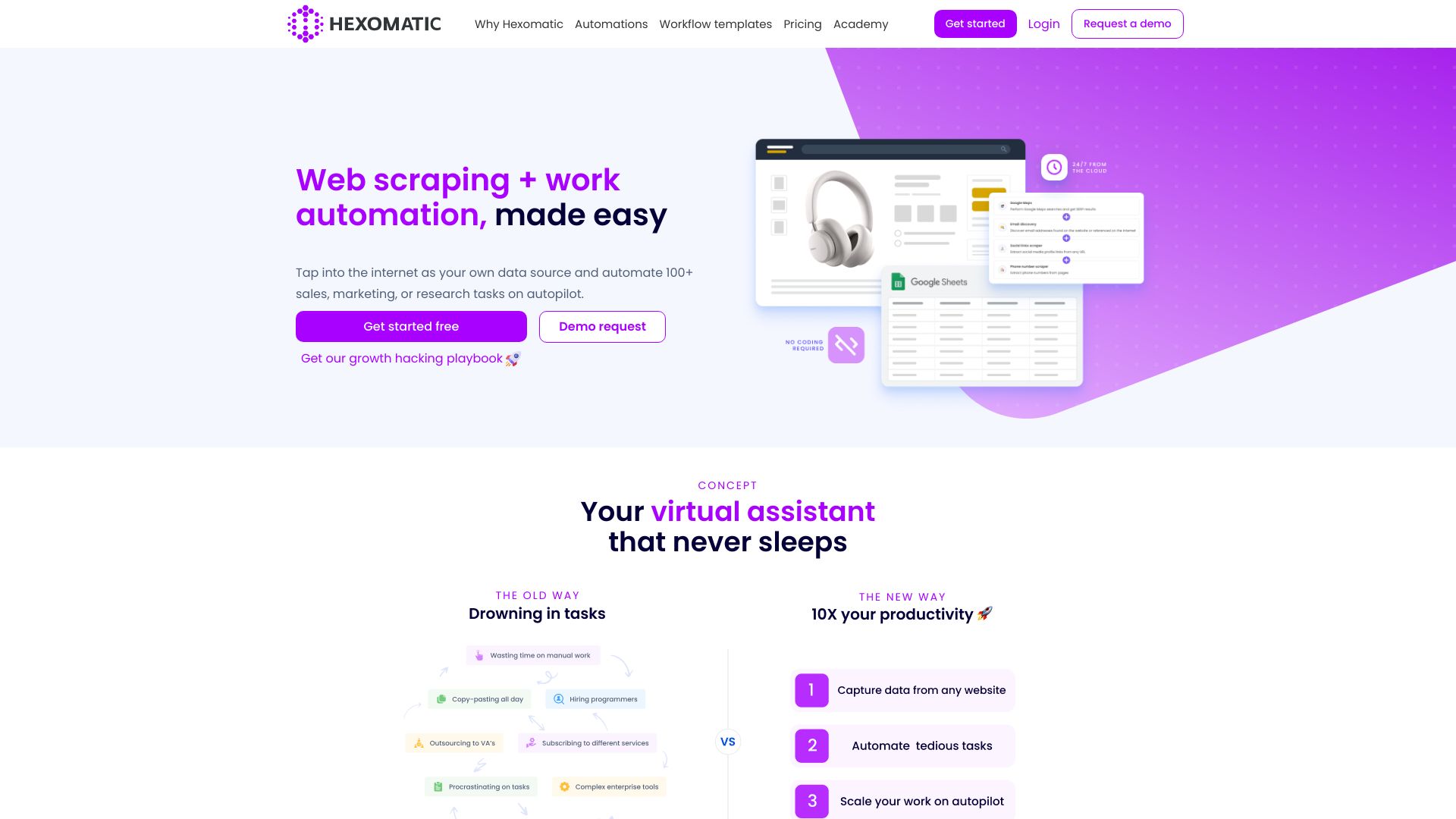
Hexomatic |
网络采集:通过一键采集器将任何网站转换成电子表格,或者创建自定义的网络采集方案 |
要使用Hexomatic,用户可以利用其网络采集功能从任何网站提取数据。他们可以使用提供的一键采集器来采集热门网站上的数据,也可以创建自己的网络采集方案。Hexomatic还提供100多个现成的自动化功能,可以对提取的数据执行各种工作任务。用户可以将自己的采集方案与现成的自动化功能结合起来,创建强大的工作流,并自动运行。 |
Kadoa |
1. 自动生成网络爬虫:Kadoa利用生成式人工智能自动创建针对不同来源的网络爬虫。 |
1. 定义要提取的数据,指定来源,并设置提取计划。 2. Kadoa生成网络爬虫,并适应网站结构的变化。 3. Kadoa准确地提取数据,并根据要求进行转换。 4. 通过强大的API以任何格式接收提取的数据。 |
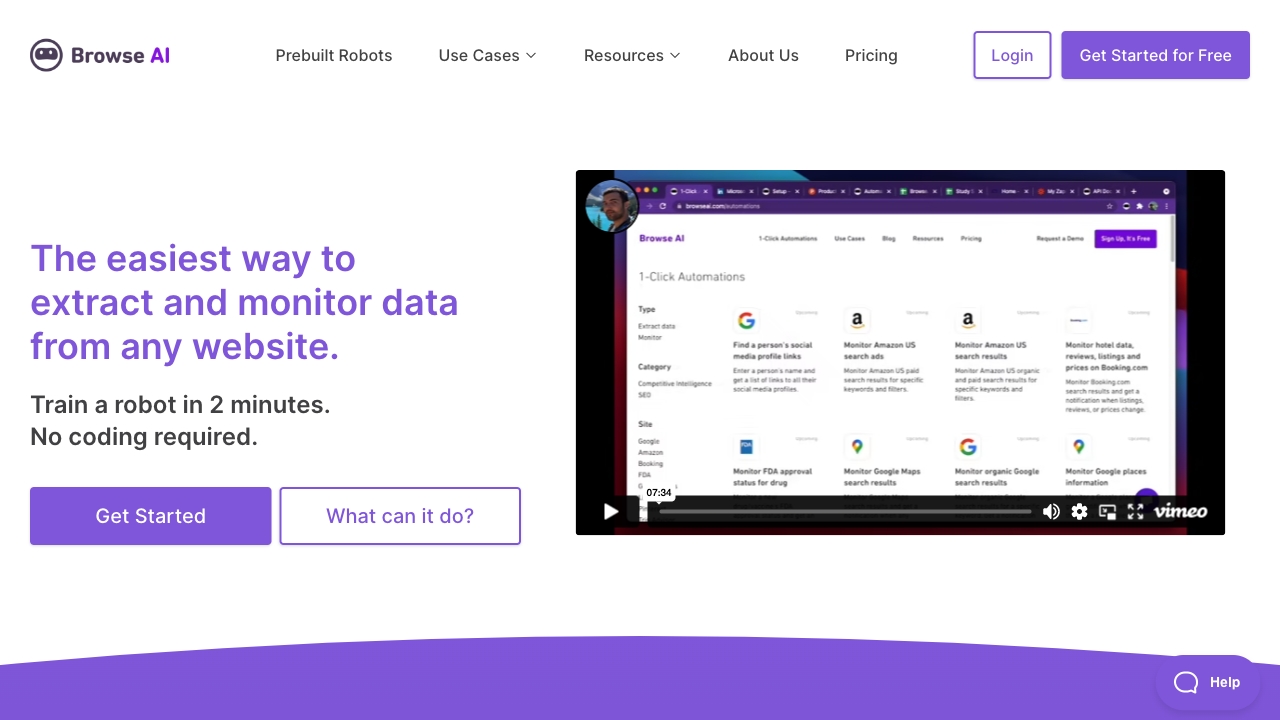
Browse AI |
数据提取:从任何网站中以电子表格形式提取特定数据。 |
使用浏览AI非常简单,只需在2分钟内完成无需编码的机器人训练。该平台提供了预先构建的机器人,供常见用例使用,可以立即使用。用户可以以电子表格形式从任何网站提取数据,安排数据提取并在变化时接收通知,并与7000多个应用程序集成。此外,浏览AI还提供处理分页,滚动,解决验证码以及全球范围内提取基于位置的数据的能力。 |
网络爬取工具 的核心功能
理解和模拟人类浏览行为
数据提取
数据结构化
数据分析
谁比较适合使用 网络爬取工具?
AI网页抓取可以被电子商务、市场营销、数据分析和寻求从大量网络数据中获得洞见的研究机构等行业的企业所使用。此外,数据科学家、市场研究员和分析师也经常使用AI网页抓取工具进行数据提取和分析。
网络爬取工具 是如何工作的?
AI网页抓取通过向目标URL发送一系列HTTP请求,然后利用机器学习算法解读、分析HTML或网页并提取有益信息,它可以模仿人类点击按钮、滚动、输入文本等操作。一旦信息被收集,通常会被处理和结构化到数据库或表格中以待进一步使用。
AI播客助手 的优势
AI网页抓取提供了值得注意的优点,如:可伸缩性 - 能够从网络上众多网页抓取数据;效率 - 高速度和准确度;成本效益 - 自动化流程可节省宝贵的时间和资源;多功能性 - 可以应用于多个领域和行业。